Information Extraction
The first stone of our pipeline is extracting main entities from french invoices. This can be done with three different methods :
1.Using a VLM :
VLM(Vision Language models) like LLaVA-7b, Llama-Vision3.2 are multimodal models designed to process both visual and textual information. They can be fine-tuned or used out-of-the-box to extract structured data from documents like invoices by processing images directly and generating textual outputs.
To test this approach we used Llama-Vision-11b with Langchain and Ollama, all the Code here in a colab notebook.
2.Using LLM :
2.1 With a Document Parser
An alternative approach involves a Document Parser to extract text and structure it into Markdown format. Passing this structured text to an LLM for processing and extracting key information.

A question should be asked here is Why using a Document Parser ?, because LLMs understand markdown text better. Besides to preserving the Invoice’s layout and tabulated data in a proper format.
There are many options like : Upstage API, MegaParse, Docling… but keep in mind that we want our tool’s inference to be 100% with local and limited resources. So we decided to countinue with Docling of IBM.
To understand better the benifit of a Document Parser, here is a video from MegaParse github repository :
Note
A hands-on example of this pipeline can be found in colab notebook.
Hint
Before jumping into the next colab insure that you close the previous one and reconnect to the Colab GPU in order to free the memory space avoiding OutOfMemory error.
2.2 With an OCR
OCR (Optical Character Recognition) Converts the invoice into machine-readable plain text by extracting text data from the Invoice.
LLM (Large Language Model): The text is processed by an LLM.
🎉 Output: The processed information is presented in a structered json format.

For the OCR-Engine there are alot of options like PaddleOCR, EasyOCR, Tesseract, docTR, …
A Blog by Roboflow countain a good bechamrking of 4 OCR models (docTR, EasyOCR, Tesseract, Surya) Show that EasyOCR has the best accuarcy/speed ratio.
Another comparaison between EasyOCR and Paddle by Christian Weiler here on 400 real invoices, show that EasyOCR has the best metrics.

3.Benchmarking :
We have now three available methods to extract information from invoices. To decide which one is the best we have to compare them.
The methodology is straightforward, first we should counstarct our grounding truth small dataset of extracted informations from Invoices, these can be done using GPT4 because is so good on that.
Then we can compare each approach outputs with the grounding truth, and calculate Accuaracy.
Three Benchmarks are Considered: Accuracy, Inference time (s) and Cost.
The Grounding Truth dataset will be in a form of a csv file. We will focus on Entities like :
TT, TTC, TVA, Date de facture, Numero facture, Supplier Name.
All the Bechmarking process is done with a L4 machine (24GB in Vram, 16 Cores).
3.1 Levenshtein distance (Edit distance)
Levenshtein distance is a measure of the similarity between two strings, which takes into account the number of insertion, deletion and substitution operations needed to transform one string into the other. Operations in Levenshtein distance are:
Insertion: Adding a character to string A.
Deletion: Removing a character from string A.
Replacement: Replacing a character in string A with another character.
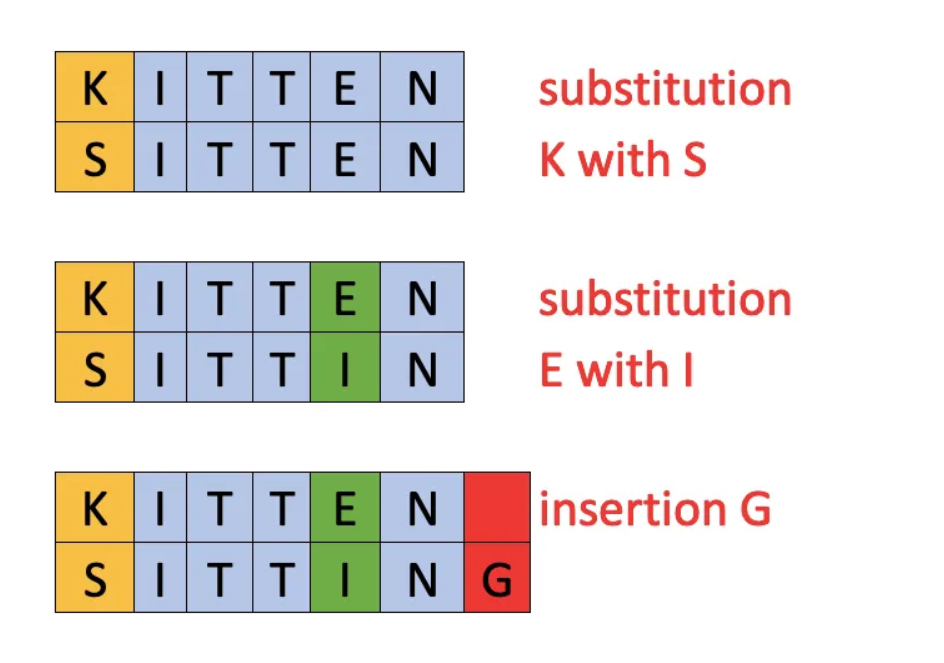
Example :
Let’s see an example that there is String A: kitten which need to be converted in String B: sitting so we need to determine the minimum operation required
kitten → sitten (substitution of k by s) sitten → sittin (substitution of e by i) sittin → sitting (insertion of g at the end).
In this case it took three operation do this, so the levenshtein distance will be 3.
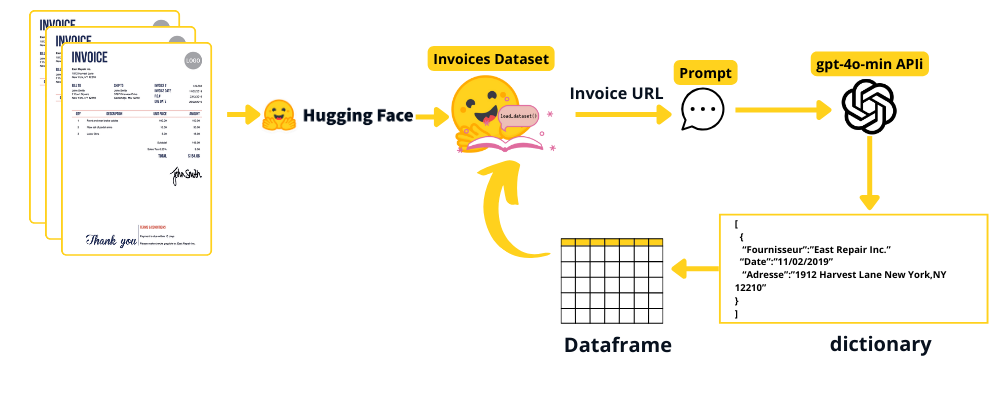
3.2 Grounding Truth
To prompt GPT4 with an Image using an api, there are two main ways:
Using the base64 encoding of the image and passing it to the api with the prompt.
Using the url of the image with the prompt.
Because we have a height images quality the encoding string becomes too long leading to an API-error (we exceed the max number of input tokens).
So a good option is providing the URL.
We choose randomly 30 invoices for the grounding truth we upload them to a HuggingFace Dataset.
Note
You may refine the gpt-results by hand, so you get accuarate dataset.
You can get a free GPT-4o-mini api key using Github models but pay attention to the rate limit.
All the implimentation Code in a colab notebook here :
After constructing the Grounding Truth dataset, we can now benchmark the three pipelines. A detailed implimentation here:
3.2 Results and Discussion
Now it’s time to some Matplotlib, based on the obtained results we can draw some conclusions. we plot three graphs one for Efficiency, Average Accuracy (%) and Average Margin (Dh).
Efficiency is the ratio between Average Accuarcy and Average Time (s).
Hint
We test alot of models small and medium size like Qween2.5 (1.5b, 3b, 7b), we conclude that tiny models struggle with the extraction task and lead to poor metrics.
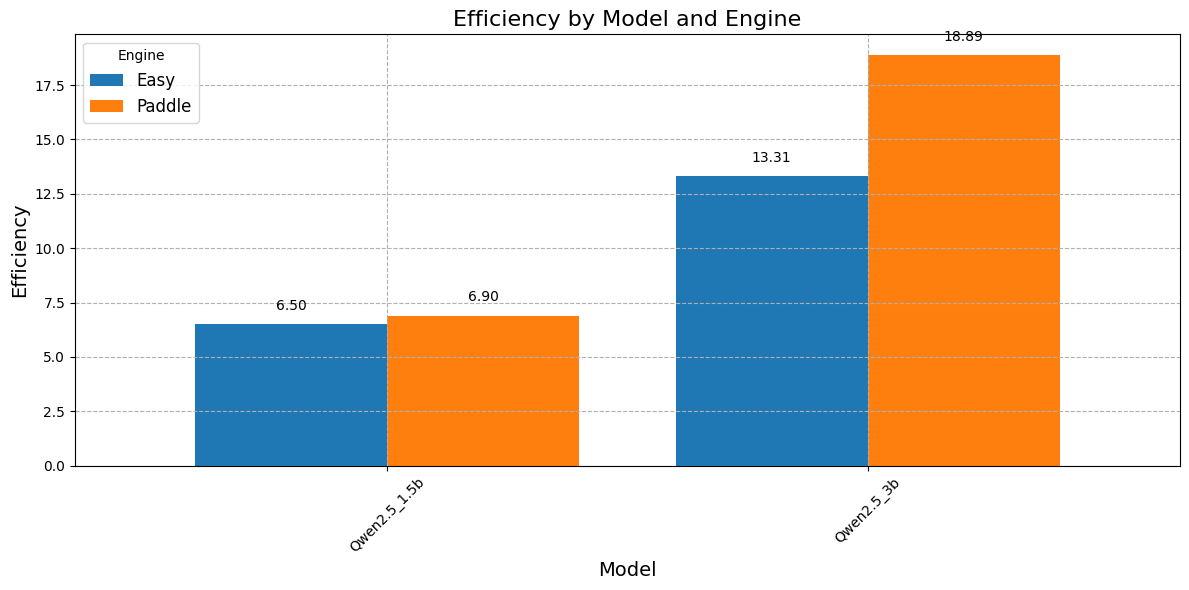
here is a plot of Efficiency by 3 famous medium size models :
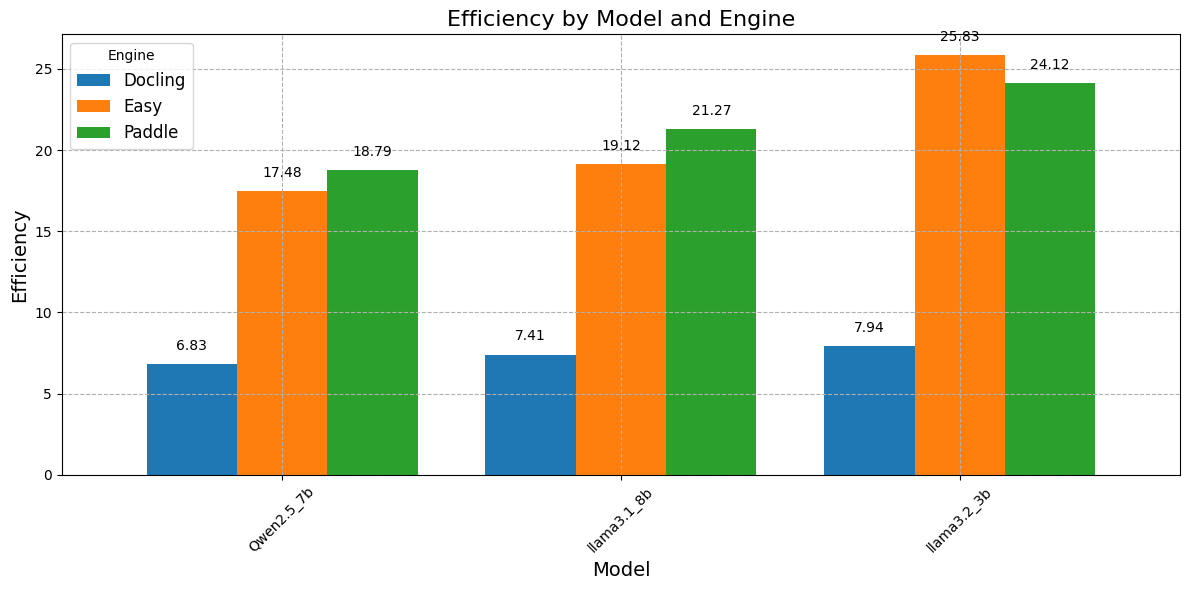
Paddle consistently shows the highest efficiency across all models compared to other engines.
Easy performs better than Docling for all models, but is slightly less efficient than Paddle.
Docling has the lowest efficiency across all models, indicating it is less optimal in performance.this because it is slower than other engines.
The best combinition may be llama3.2-3b + EasyOCR.
and here is a plot of Average Accuracy (%) :
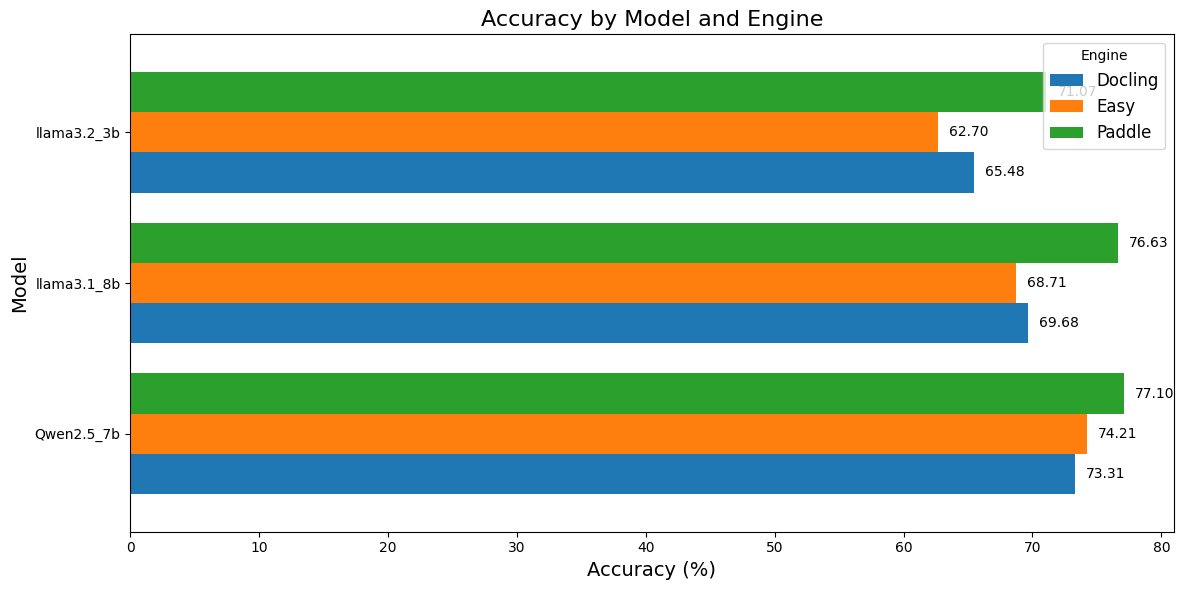
Paddle achieves the highest accuracy across all models, confirming its dominance in both performance and reliability.
Qween2.5-7b and llama3.1-8b show the highest accuarcy with paddle, which is expected regards to their size.
llama3.2-3b perform also well even with his small size.
the last plot is for Average Margin (Dh) which is the difference between the predicted and the ground truth prices.
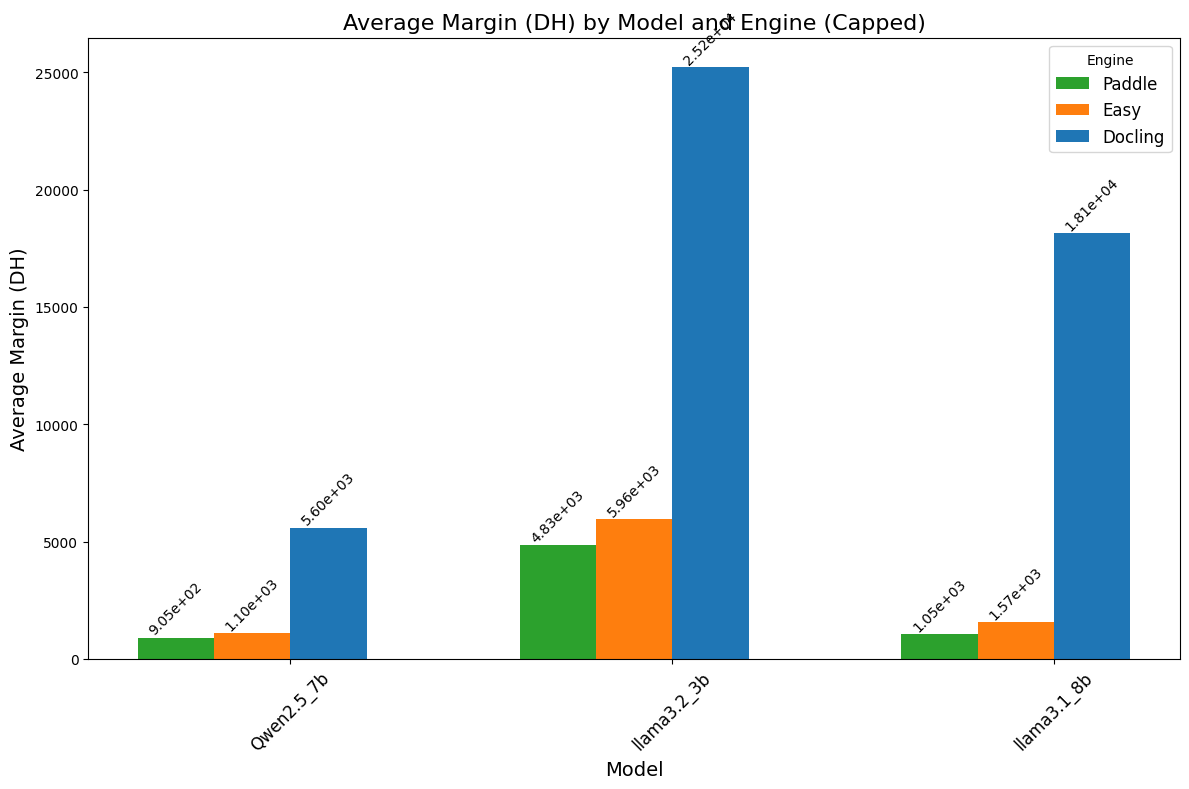
Paddle and EasyOCR are slightly the same in terms of margin.
Docling is less accurate which gives the highest margins.
Qween2.5-7b and llama3.1-8b give good results.
Note
It was expected that Docling would be the best Engine, because of its markdown parsing capabilities, but it is not the case. That can be explained by bad quality ocr-backbone used by Docling.